

천천히 빛나는
Java 기초 : Collections Framework 본문

ArrayList
import java.util.ArrayList;
public class ArrayListDemo {
public static void main(String[] args) {
ArrayList al = new ArrayList(); // Object 타입
al.add("one"); // 넣은건 String이지만 Object 타입으로 저장이 되어짐 => String이 아님!
al.add("two");
al.add("three");
}
}연관된 데이터를 관리하는 배열 -> 배열의 크기를 변경할 수 없음
이러한 문제를 해결할 수 있는 것을 Collections Framework가 제공하게 된다. 이 중 ArrayList가 Collections Framework의 기능 중 하나이다.
for(int i=0; i<al.size(); i++){ // 배열은 length
System.out.println(al.get(i)); // 배열은 arr[i];
}배열과 다르게 ArrayList는 size()로 크기를 가져오고 .get(i)를 롱해서 값에 접근할 수 있다.
for(int i=0; i<al.size(); i++){ // 배열은 length
String val = al.get(i); // 오류 발생
String val2 = (String)al.get(i); // 형변환 해주어야 함
}ArrayList 내에서 add를 통해서 입력된 값은 Object의 데이터 타입을 가지고 있고, get을 이용해서 이를 꺼내도 Object의 데이터 타입을 가지고 있게 된다.
get의 리턴값을 형변환해줄 수 있지만 아래와 같은 제너릭 방식을 사용하는 것이 좋다.
ArrayList<String> al = new ArrayList<String>();
ArrayList<String> al = new ArrayList<>(); // 위와 동일제네릭을 사용하면 ArrayList 내에서 사용할 데이터 타입을 인스턴스를 생성할 때 지정할 수 있기 때문에 데이터를 꺼낼 때(String val = al.get(i);) 형변환을 하지 않아도 된다.
Collections Framework

Collections Framework에는 Collection과 Map이라는 최상위 카테고리가 있고 그 아래에는 기능에 따라서 Set, List, Queue라는 것이 있다. List 아래에도 ArrayList, Vector, LinkedList가 있고 Set 아래에도 HashSet, LinkedHashSet, TreeSet이 있다.
자신이 하려고 있는 일에 따라 적당한 구성요소를 선택할 수 있어야 한다. 배열과 비슷하지만 크기가 자동으로 커질 수 있는 프레임워크(컨테이너)가 필요하다면 List안에서 하나를 골라야 하며 관리데이터가 중복되지 않아야 한다면 Set에서 하나를 골라야 한다. 또한 key, value 값이 필요하다면 Map을 고르면 된다.

Set
Set은 한국어로 집합이라는 뜻이다. 여기서의 집합이란 수학의 집합과 같은 의미다. 수학에서의 집합도 순서가 없고 중복되지 않는 특성이 있다
import java.util.HashSet;
public class ListSetDemo {
public static void main(String[] args) {
HashSet<Integer> A = new HashSet<Integer>();
A.add(1);
A.add(2);
A.add(2);
A.add(2);
A.add(2);
A.add(3);
Iterator hi = (Iterator) A.iterator();
while(hi.hasNext()){
System.out.println(hi.next());
}
// 1, 2, 3만 출력된다
}
}ArrayList의 경우에는 1, 2, 2, 2, 2, 3이 출력되겠지만 Set은 1, 2, 3만 출력이 된다. List와 Set의 차이점은 List는 중복을 허용하고, Set은 허용하지 않는다는 점이다.
Iterator 에 대해서는 지금 신경쓸 필요는 없고 출력하는데 사용하고 있다는 것말 알아두면 된다. (추후 서술)
import java.util.HashSet;
public class ListSetDemo {
public static void main(String[] args) {
HashSet<Integer> A = new HashSet<Integer>();
A.add(1);
A.add(2);
A.add(3);
HashSet<Integer> B = new HashSet<Integer>();
B.add(3);
B.add(4);
B.add(5);
HashSet<Integer> C = new HashSet<Integer>();
C.add(1);
C.add(2);
// 부분집합 (subset)
System.out.println(A.containsAll(B)) // false
System.out.println(A.containsAll(C)); // true
// 합집합 (union)
A.addAll(B); // A = 1, 2, 3, 4, 5
// 교집합 (intersect)
A.retainAll(B); // A = 3
// 차집합 (difference)
A.removeAll(B); // A = 1, 2
}
}집합에서 교집합(intersect), 차집합(diffrence), 합집합(union)과 같은 연산을 할 수 있다.
- 부분집합 : A.containsAll(B); // B가 A에 모두 포함되는지 boolean
- 합집합 : A.addAll(B); // A 출력해보면 합집합 출력됨
- 교집합 : A.retainALL(B); // A 출력해보면 교집합 출력됨
- 차집합 : A.removeAll(B); // A 출력해보면 A-B된 값 출력
Set은 순서대로 저장하는 것을 보장하지 않는다. 하지만 List는 순서대로 저장하는 것을 보장한다. Set은 순서가 없는 것이기 때문이다.
Iterator
메소드 iterator은 인터페이스 Collection에 정의되어 있다. 즉Collection을 구현하고 있는 모든 컬렉션즈 프레임워크는 이 메소드를 구현하고 있다. 메소드 iterator를 호출하면 인터페이스 iterator를 구현한 객체를 반환하게 된다. iterator은 아래 3개의 메소드를 구현하도록 강제하고 있는데 각 역할을 다음과 같다.
Iterator hi = (Iterator) A.iterator();
while(hi.hasNext()){
System.out.println(hi.next());
}
}- hasNext : 반복할 데이터가 있으면 true, 없으면 false
- next : 다음값

Iterator의 next 함수를 호출하면 값을 return하고 값이 사라진다. (A에서는 사라지지 않는다!)
Collection<Integer> A = new HashSet<Integer>();
A = new ArarryList<>();
A = TreeSet<>();
Map
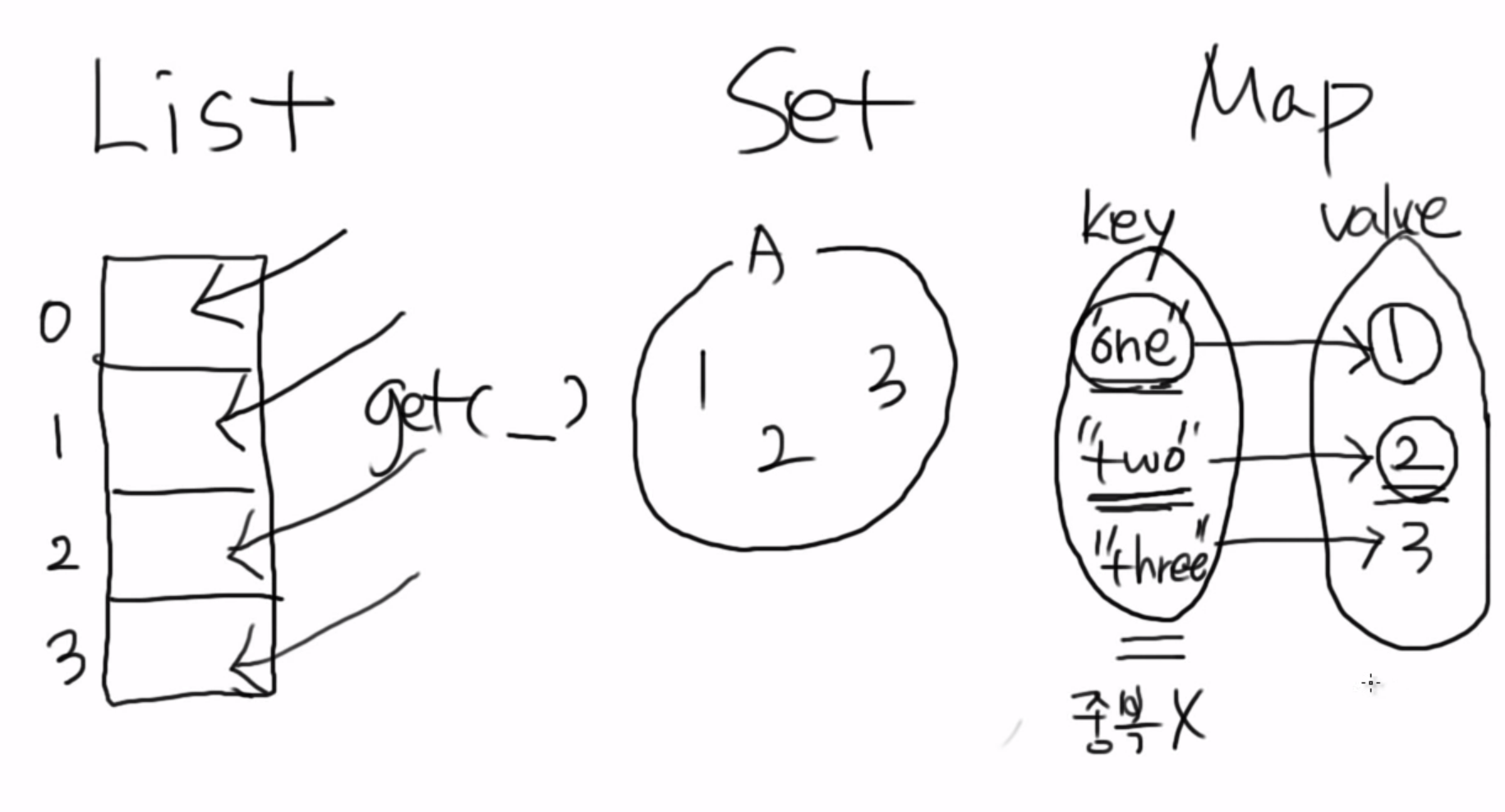
Map에서 key는 중복이 불가능하고 value는 중복이 가능하다.
import java.util.*;
public class MapDemo {
public static void main(String[] args) {
HashMap<String, Integer> a = new HashMap<String, Integer>();
a.put("one", 1); // Map에만 존재하는 메소드!!!
a.put("two", 2); // (key, value);
a.put("three", 3);
a.put("four", 4);
System.out.println(a.get("one"));
System.out.println(a.get("two"));
System.out.println(a.get("three"));
iteratorUsingForEach(a);
iteratorUsingIterator(a);
}
static void iteratorUsingForEach(HashMap map){
Set<Map.Entry<String, Integer>> entries = map.entrySet();
for (Map.Entry<String, Integer> entry : entries) {
System.out.println(entry.getKey() + " : " + entry.getValue());
}
}
static void iteratorUsingIterator(HashMap map){
Set<Map.Entry<String, Integer>> entries = map.entrySet();
Iterator<Map.Entry<String, Integer>> i = entries.iterator();
while(i.hasNext()){
Map.Entry<String, Integer> entry = i.next();
System.out.println(entry.getKey()+" : "+entry.getValue());
}
}
}- put : Map에서만 사용 (key, value)
- get(key) : key에 해당하는 value를 return
- entrySet() : Map 컨테이너를 Set 데이터 타입으로 변경
메소드 entrySet은 Map의 데이터를 담고 있는 Set을 반환한다. 반환한 Set의 값이 사용할 데이터 타입은 Map.Entry이다. Map.Entry는 인터페이스인데 아래와 같은 API를 가지고 있다.
- getKey
- getValue
Map을 Set으로 변환했을 때 Set 안에 들어있는 것이 Map.entry이고 getKey()와 getValue()를 호출할 수 있다.
정렬
컬렉션을 사용하는 이유 중 하나는 정력과 같은 데이터 작업을 하기 위해서이다.
Collections.sort(list_name); // static 이라서 클래스로 호출 가능sort 함수에서는compareTo 메소드를 통해서 정렬을 하게 된다.
public int compareTo(Object o) {
return this.serial - ((Computer)o).serial;
}메소드 sort를 실행하면 내부적으로 compareTo를 실행하고 그 결과에 따라서 객체의 선후 관계를 판별하게 된다.
양수면 현재 객체가 큰거고 음수면 인자로 전달된 객체가 큰 것이 된다.
'JAVA > JAVA' 카테고리의 다른 글
| Java 기초 : 다형성 (Polymorphism) (0) | 2024.01.17 |
|---|---|
| Java 기초 : 인터페이스 (interface) (0) | 2024.01.17 |
| Java 기초 : 접근 제어자 & Abstract & final (0) | 2024.01.16 |
| Java 기초 : API와 API 문서 보는 법 (0) | 2024.01.16 |
| Java 기초 : 클래스 패스와 패키지 (0) | 2024.01.15 |



