

천천히 빛나는
알고리즘: 시간 복잡도란 본문
본격적으로 시간복잡도 문제를 풀기 전에, 시간 복잡도에 대해 설명하도록 하겠다. 이 설명은 시간복잡도를 들어는 봤으나 정확히 개념을 모르겠거나 까먹은 전공자들이 읽어야 이해가 될 것이다.
시간 복잡도란?
코드를 실행해보기 전에 반복문, 입력값 등을 통해서 실행시간이 얼마나 걸릴지 추측할 수 있는 척도
보통 Big-O 표기법으로 최악의 상황일 때 걸리는 시간을 이용해서 나타낸다.
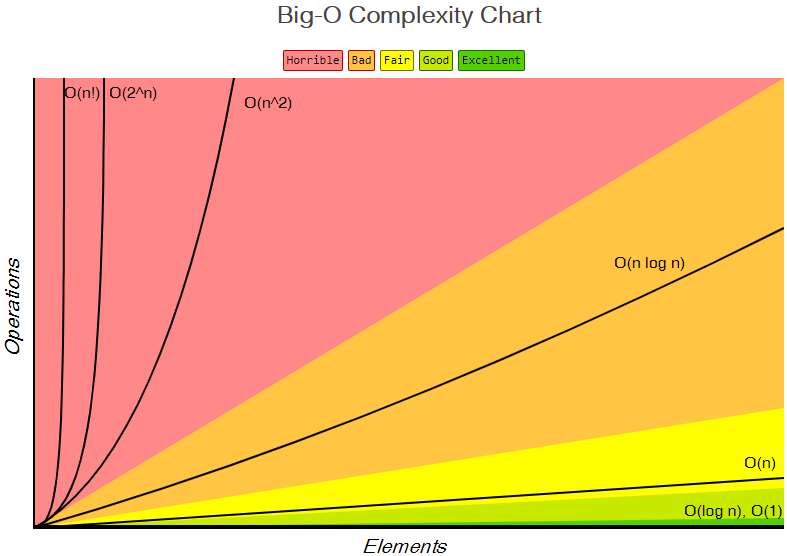
x축은 자료의 수, y축은 걸리는 시간이다. 즉 빨간 부분에 있을 수록 수행 시간이 굉장히 오래 걸리는 알고리즘이다
1) O(1)
cout << "hello!";if(input % 2 == 0) {
cout << "짝수";
} else {
count << "홀수";
}입력 크기와 상관없이 고정된 시간으로 계산되는 경우이다. 홀수면 두 단계를 걸치게 되지만 이 또한 O(1)로 나타낸다. 아주 사소한 차이이기 때문이다.
2) O(n)
for(int i=0;i<input;i++){
cout << "hello!";
}
for(int i=0;i<input;i++){
cout << "hello!";
}for문이 2개 있지만 O(n)이다. 시간복잡도 계산에는 가장 큰 영향을 미치는 알고리즘 하나만 계산한다.
input값이 커짐에 따라 연산을 비례하여 수행하게 되므로 O(n)이라고 이해하면 된다.
3) O(n^2)
for(int i=0;i<input;i++){
for(int j=0;j<input;j++{
cout << "hello!";
}
}for(int i=0;i<input;i++){
for(int j=i;j<input;j++{
cout<<"hello!";
}
}
for(int i=0;i<input;i++){
cout<<"hello!";
}input만큼 반복하는 이중 for문이 있으므로 O(n^2)이 된다. 두번째 코드도 마찬가지로 O(n^2)이 된다. 그렇다면 O(n^3)은 삼중 for문이 된다는 것을 예상할 수 있다.
4)O(nm)
for(int i=0; i<input1; i++) {
for(int j=0; j<input2; j++) {
cout<<"hello!";
}
}n번 반복문과 m번 반복문을 중첩시켰다고 생각하면 된다.
5) O(2^n)
int pibo(int input) {
if (input == 0) return 0;
else if (input == 1) return 1;
return pibo(input - 1) + pibo(input - 2);
}대표적으로 피보나치 수열이 이에 해당된다. 위 코드는 input번째 피보나치 수열값을 구하는 함수이다. n번째 항과 n+1번째 항을 더한 값이 n+2번째 항이 된다.

한번 호출 할때마다 2씩 곱해진 값으로 커지게 된다.
1번 호출 -> 2개 생성
2번 호출 -> 2개 생성 -> 4개 생성
그래서 O(2^n)이 되는 것이다.
6) O(logn)
int binarySeacrh(int[] num, int target, int low, int high) {
int mid = (low + high) / 2;
if(target == num[mid]) return mid;
else if(target < num[mid]) return binarySeacrh(num, target, low, mid-1);
else return binarySeacrh(num, target, mid+1, high);
}이진 탐색 기법을 코드로 구현한 것이다. 탐색을 할 수록 데이터가 절반이 되므로 O(logn)이 된다.
예를 들어 크기가 8인 배열이 있으면 탐색할때마다 8=>4=>2=>1로 줄어들어서 3번의 시행으로 찾을 수가 있다.
7) O(nlogn)
퀵정렬, 합병 정렬, 힙 정렬이 있다. 정렬 파트는 뒷 부분에서 다룰 거라서 정렬을 다룰 때 이 밑에 링크를 걸어두도록 하겠다.
모든 코드에서 계산할 때 잊지 말아야할 부분이다.
- 상수항 무시
- 영향력 낮은 항 무시
최종적으로 O()에 들어갈 식을 계산해서 1억당 1초 정도로 생각할 수 있다. n이 1억이고 O(n)이면 1초 정도 걸리는 것이고, n이 1억, m이 10이면 10억이므로 10초 정도 걸리게 되는 것이다.
대략적인 소요 시간을 추측할 수 있으나 보통 코테를 볼 때 하나하나 계산하면서 짜기에는 어렵다고 한다.
[알고리즘] 시간복잡도 예제 15종 | 블로그 | 딩그르르
[알고리즘] 시간복잡도 예제 15종
dingrr.com
시간 복잡도를 공부하는 대학생이라면 위에 걸어둔 링크에 들어가서 문제를 풀어봐도 좋을 것 같다
'STUDY > ALGORITHM' 카테고리의 다른 글
| 알고리즘 : 자료구조(3) 덱 (Deque) (C++로 구현) (1) | 2023.09.19 |
|---|---|
| 알고리즘 : 자료구조(2) 큐 (Queue) (C++로 구현) (0) | 2023.09.18 |
| 알고리즘 : 자료구조(1) 스택 (Stack) (C++로 구현) (0) | 2023.09.18 |
| 알고리즘 : 정렬이란? (C++로 구현) (0) | 2023.09.16 |
| 알고리즘 : 브루트 포스란 (0) | 2023.09.10 |



